לפני זמן מה עבדתי עם לקוח שהמודל העסקי שלו היה מכירה של דוחות עומק ייחודיים. כל דו”ח דרש שבועות של עבודה להפיק ובהתאם עלה ללקוחות סכום נאה של אלפי דולרים.
כשביצעתי בדיקה שגרתית של בריאות האתר בכלי מנהלי האתרים של גוגל (Search Console/Webmaster Tools), מצאתי שהאתר של הלקוח מדורג עבור הביטוי המדויק של שם הדוח העדכני שהופק. בדרך כלל היית מצפה שאלו יהיו חדשות טובות, אך מאחר ולא היה עמוד שכזה באתר זה הדליק לי נורה אדומה. כשהתעמקנו בתוצאות, ראינו שהעמוד המדורג הוא בעצם הדוח עצמו, באופן שהוא חשוף לכל גולש.
כמובן שמיד עשינו את הצעדים הנדרשים לחסימה של התוכן החשוף, אבל הסוגיה הזאת מדגישה את אחד המקומות בהם גוגל אנליטיקס אינו מסוגל להראות לנו את כל התמונה.
איך זה קורה?
הסורק של גוגל (aka Googlebot) מסוגל לקרוא ולאנדקס מסמכים באותו אופן כמו עמודי HTML. הפורמטים הנפוצים שניתן למצוא בתוצאות החיפוש הם doc/docx (מסמכי וורד) או קבצי PDF, אך ישנם מקרים בהם גם מצגות פאוורפוינט או קבצי אקסל יאונדקסו גם כן. ואם גוגל מוצא אותם רלוונטיים, הוא יציג אותם כתוצאה אורגנית לצד עמודי HTML רגילים.
משתמש שלוחץ על מסמך שכזה אינו נספר על ידי גוגל אנליטיקס מאחר ומסמכים אלו אינם יכולים להכיל קוד JavaScript פעיל. לכן הדרך היחידה לקבל אומדן עבור התנועה למסמכים שכאלה היא באמצעות דוח Search Analytics בכלי מנהלי האתרים. מבדיקה מדגמית שעשיתי בחשבונות הלקוחות שלי, גיליתי טווח של 5-15% מהתנועה האורגנית שנוחתת בעמודים מסוג זה. זאת כמות משמעותית מדי בכדי שתעבור מתחת לרדאר.
אבל למה זה רע בעצם?
הסיבה הראשונה והבסיסית היא – לא ניתן למדוד את זה. מעין “עץ נופל ביער” עם גולשים באתר שלך.
הסיבה השנייה, בהמשך ישיר לראשונה, היא שמה שלא ניתן למדוד לא ניתן לשפר (ואם זה מצוין – לשכפל). אני רוצה לדעת אם אנשים קראו את התוכן שלי עד סופו או שעשו מיד באונס. כיצד הגיעו אליו ולאן המשיכו ממנו.
מדדים אלו לא רק ישפרו את פיסת התוכן הספציפית אלא יעזרו לי לשפר את סך התוכן והחוויה של הגולש באתר.
כך שאם תוכן מסוים מדורג על ביטוי שהוא חשוב לי, אני חייב לדעת את הפרטים, קטנים וגדולים כאחד.
אז איפה מתחילים?
שלב א’ – זהה את התוכן החשוף
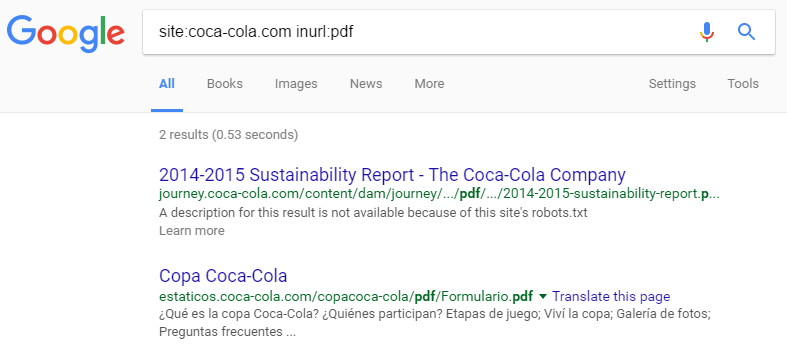
התחילו במיפוי של כל התוכן שגוגל כבר מכיר עבור הדומיין שלך. בשביל זה נבצע חיפוש בגוגל שמתמקד בדומיין שלנו בלבד ומחפש בו סיומות מוכרות.
site:mydomain.com inurl:pdf
(חלופה נוספת במקום inurl:pdf היא filetype:pdf)
חיפוש זה יציג לי את כל העמודים באתר הכוללים את הביטוי PDF ב-URL, וממילא את ה-PDF-ים הקיימים.
הדוגמה בפוסט תהיה סביב מסמכים מסוג PDF אך רלוונטית לכל סוגי המסמכים.
ניתן גם להגביל את החיפוש לסאבדומיין מסוים, למשל blog.mydomain.com.
טיפ של אלופים:
בחיפוש שכזה גוגל עשוי להשמיט תוצאות דומות ולכן חשוב ללחוץ על
“If you like, you can repeat the search with the omitted results included.”
תעברו על התוצאות ותזהו מסמכים שלא רציתם שיופיעו: מסמכים פנימיים, תוכן שאמור להיות מוגן בטופס לידים וכד’.
שלב ב’ – בדיקו איזה תוכן מקבל תנועה בפועל
אחרי שמצאנו איזה תוכן חשוף, נעבור לבחון איזה תוכן מדורג אורגנית ומקבל תנועה בפועל.
בכדי לעשות זאת ניכנס לכלי מנהלי האתרים לדוח Search Analytics. בדוח יש לעבור ללשונית Pages ובה לפלטר עמודים הכוללים PDF.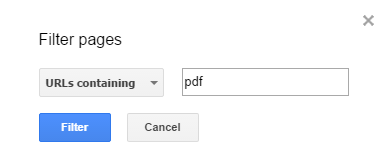
טיפ של אלופים:
בלשונית עמודים, הקלקה על עמוד מסוים תגביל את הנתונים עבור אתו עמוד בלבד ואז במעבר ללשונית Queries ניתן לראות את כל הביטויים עבורם אותו עמוד מדורג.
עכשיו ניתן לראת אילו מסמכים מביאים תנועה בפועל ולקבל אומדן של הblindspot שקיים לך.
ומה עושים עם כל זה?
ובכן, It’s complicated.
מקרה א’ – דירוג גבוה עבור ביטוי מפתח משמעותי
במקרים מסוימים, טוב לנו לקבל את הדירוג הזה. ואז לא נרצה להסתכן בנזק בדירוג על ידי שינויים משמעותיים.
יש לבחון את המסמך המסוים: האם הוא עושה שימוש בתוכן עדכני? האם המיתוג שלו עדיין תואם את שאר הנכסים שלנו? האם הקישורים היוצאים ממנו לאתר מתויגים?
אם צריך תיקונים קלים, ניתן להעלות את הקובץ שוב לשרת על אותה הכתובת ולשמור על הכוח הקיים של המסמך.
אם זה מסמך שמקבל תנועה משמעותית, חשוב לוודא שקיימות בו קריאות לפעולה (מתויגות!) שמובילות חזרה לאתר המלא.
מקרה ב’ – דירוג נמוך עבור ביטוי מפתח
בסופו של יום, עמודי HTML לרוב ידורגו גבוה מאשר מסמכים. זה נובע בפשטות ממספר האינדיקטורים הזמינים עבור גוגל בכדי לפרש את העמוד לעומת מסמך. כך שאם לדוגמה מסמך מתחרה על ביטוי מסוים ומגיע רק לעמוד שני, יש לשקול להסב את המסמך לעמוד באתר. התוכן של המסמך יכול לשמש כבסיס לתוכן העמוד וכמובן שיש ליצור הפניית 301 מכתובת המסמך לעמוד החדש. הוספה של תוכן נוסף על הקיים במסמך (תמונות, וידאו וכד’) תהיה משמעותית גם כן.
מקרה ג’ – תוכן שהיה אמור להיות נעול
במקרה שכזה, הברירה הטובה ביותר היא הפנייה לעמוד שבו קיימת ה”חומה” הרלוונטית (טופס לידים בד”כ).
הפתרון הפשוט הוא ביצוע של הפניית 301 אשר תחליף את כתובת המסמך בכתובת העמוד החדש.
הפתרון העדיף הוא ביצוע הפנייה תוך החזרת קוד 401 לסורק של גוגל. הפנייה זו תאותת לסורק כי התוכן עדיין שם אבל אינו זמין ללא הזדהות מצד הגולש.
טיפ של אלופים:
בשני המקרים, בכדי לשמור על כוחו האורגני של המסמך בעמוד המטרה, יש לנסות לשלב חלק מהטקסט של המסמך בעמוד עצמו. זה יכול להיות מעין מבוא או תיאור של המסמך, דבר שהוא גם בעל ערך עבור הגולש שיידרש להשאיר פרטים בכדי שיוכל לראות אותו.
לסיכום
ניתן לצפות כי התופעה הזו תתרחש באתרים ותיקים שנמצאים באוויר כבר תקופה ארוכה. במרבית המקרים מצאתי כי זהו תוכן ישן יחסית אשר הצליח במשך הזמן לתפוס דירוג אורגני שחמק מתחת לרדאר.
מי שעושה שימוש בכלי מעקב מיקומים בגוגל יכול לקבל את סוג התוצאה שמדורגת עבור הדומיין שלו (עמוד HTML, מסמך, תוצאה עשירה אחרת וכד’), אך גם הידיעה הזו אינה פותרת את הפער שקיים ביחס לכמות התנועה שנוחתת בתוצאות מסוג זה.
באמצעות השלבים הפשוטים שתיארתי בפוסט תוכלו גם לחשוף ולתקן את המסמכים, וגם לקבל את האומדן הקרוב ביותר לתנועה שלכם בפועל.

תאמין לי, אם לא היית – מישהו היה צריך להמציא אותך.
תודה 🙂
תודה 🙂
מאמר מעולה !
אהבתי איך שהסברת את הרלוונטיות של הנושא דרך סיפור שקרה.
מחכה למאמר הבא 🙂
דוגמה מדהימה לשילוב ידע בSEO עם דאטה מאנליטיקס.
שוקי אתה אלוף
תודה!!
מסכים בהחלט ששוקי אלוף 😉
פוסט מאוד חשוב ומאיר עיניים! תודה רבה!